Motivation
It is of great interest to the historical and literary community to be able to identify an author based on the style and structure in their texts. The authorship of many famous works is disputed or unknown, and being able to resolve the true author would lead to a greater insight into the era and people to whom the text was written. Our goal is to be able to take a sample of text whose authorship is known, and through natural language processing and machine learning determine the author of another text whose authorship is unknown.
Solution
The model classifies the author of a text sample to one of many famous authors based on training data from texts of said authors. We extracted features from the text samples using TextBlob (a natural language processing package). Many of the features we extracted were part of speech percentages. For example, adjectives, coordinating conjunctions, possessive pronouns and more. We were also able to extract sentiment, such as polarity and subjectivity, word length and sentence length. We tried tried J48, Random Forest, Naive Bayes, Bayes Net and Multilayer Perceptron on these features and found that Multilayer Perceptron worked best in 10-fold cross validation.
Training and Testing
Our dataset was composed of 76 of the top 100 books from Project Gutenberg over the last 30 days. These books were written by 56 different authors. We split up each book into many smaller samples (about 10 pages each). We used 10-fold cross validation on all the classifiers to determine which classifier most accurately classified the data. We also had a test set of 56 books that we used to test our classifier.
Results
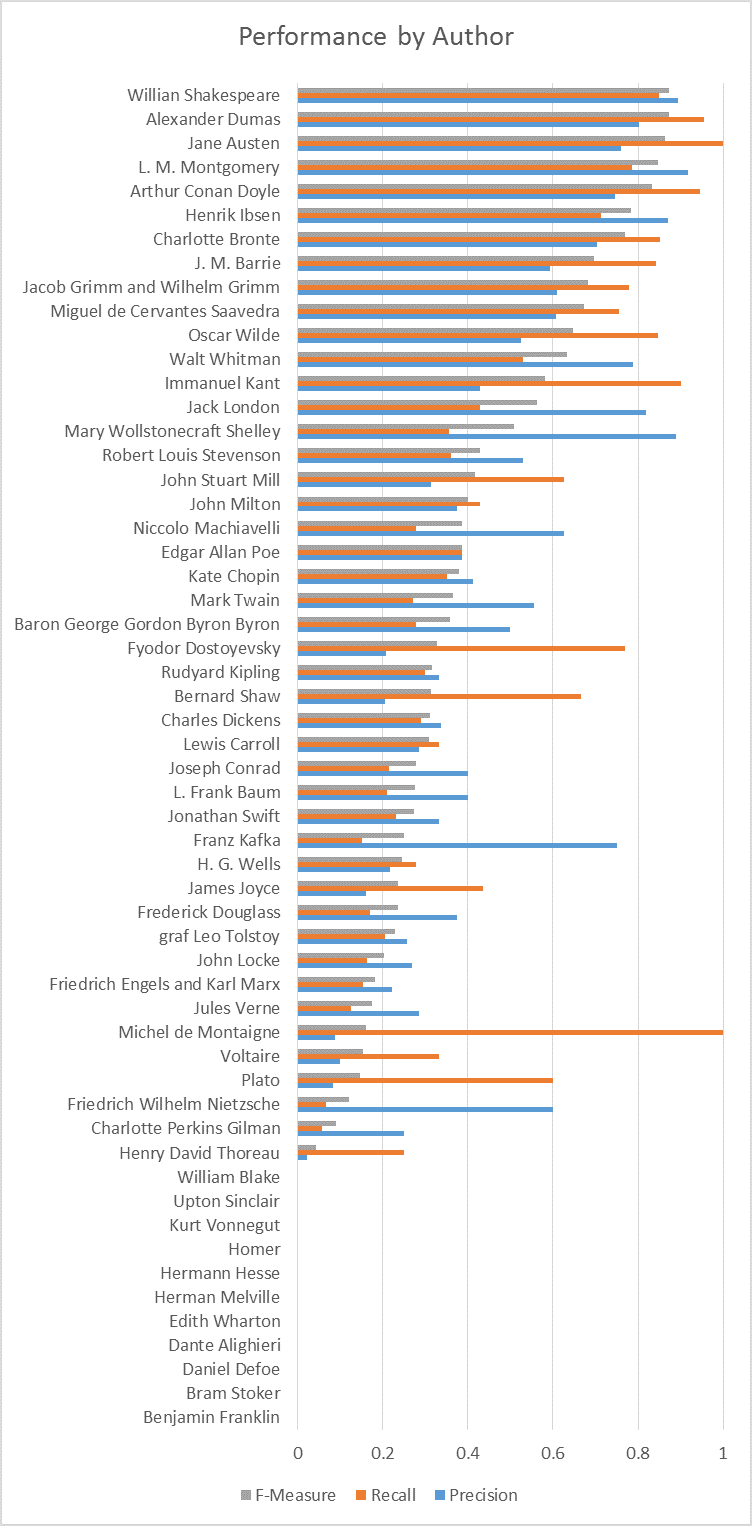
After determining that multilayer perceptron was the best classifier using 10-fold cross validation, we used the test set we had set aside previously. The test set achieved 44.146% accuracy. For comparison ZeroR had 2.686% accuracy. The output of our model on the test data suggests that authors do indeed have invariant features that can be used to identify unclassified texts. However, the scope of our training data was too small to reliably distinguish between book-invariant and author-invariant features. If the test text was from a book with a significantly different genre, type, or style the model consistently scored lower accuracy. Even with a small data set for training, the results were significantly better than random, suggesting that it is possible to find author-invariant features.
Authors and Contributors
Author Label was developed and produced by Josiah Evans (@ChosunOne, josiahevans2016 [at] u [dot] northwestern [dot] edu) and Ben Meline (@benmel, benjaminmeline2015 [at] u [dot] northwestern [dot] edu) for EECS 349 Machine Learning at Northwestern University.